|
Contributions: Text:
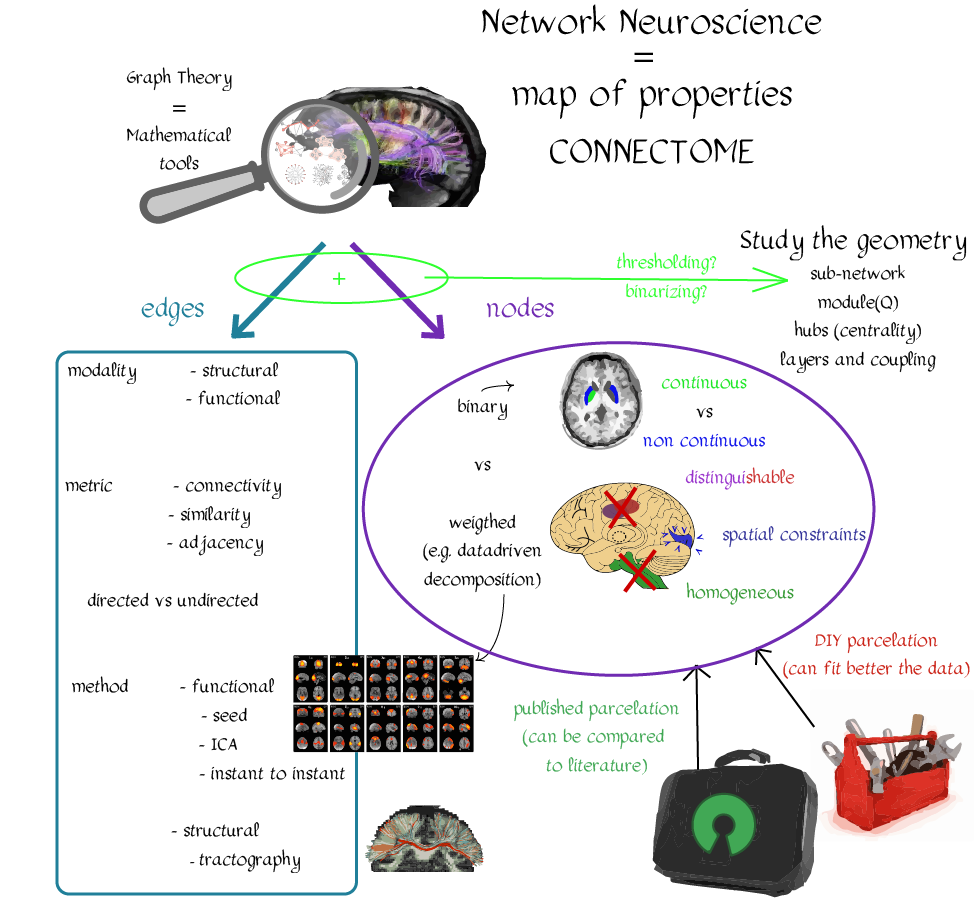 In this tutorial, we present the fundamental concepts of network neuroscience. We build upon material from the previous Educational Sessions of OHBM’s Annual meeting, available through the OHBM Youtube channel, which contains a trove of lectures, education courses, and symposia from OHBM’s annual conferences. During the virtual meeting 2020, Alex Fornito and Andrew Zalesky presented a course on Fundamental Concepts and Methods in Network Neuroscience. Speakers included Alex Fornito, Janine Bijsterbosch, Shella Keilholz, Robert Smith, Andrew Zalesky, Bratislav Misic, Richard Betzel, Ann Sizemore Blevins, Martijn van den Heuvel and Petra Ritter. We highlight material from this course, which is currently available on YouTube, so readers can learn from the experts in this condensed tutorial. I hear a lot of talk about “network approaches” to neuroscience, what does that mean? Simply put, we are interested in studying the connections, or wiring, between so-called “brain areas.” Though Franz Joseph Gall is famously known for the pseudoscience of phrenology, his underlying idea that different parts of the brain perform different functions has informed much of modern neuroscience. This phenomenon of functional localization, often referred to as functional segregation or separation, has been thoroughly investigated down to individual neurons. However, as Alex Fornito points out at the beginning of the education course, though this degree of specification is a fundamental property of brain organisation, the experiences that are constructed by the human brain are not thought to be formed by independent, disconnected processes. Rather, specialized processes are integrated together through connections between different brain regions. This apparent functional integration occurs over multiple spatial and temporal scales and heavily depends on the connections between different neural elements, which can be studied at macroscopic resolutions using magnetic resonance imaging (MRI). The brain has more than 85 billion neurons, which show an extraordinary level of local interconnectivity and highly organized long-range connectivity. In this respect, the brain’s organization resembles that of other complex systems observed throughout nature and in our everyday lives. For example, the world wide web is a network that links each of us to pretty much anyone anywhere in the world at any time. One of the principal aims of network neuroscience is to try to understand the properties of brain networks. As explained by Alex at 5:30 min, network neuroscience aims to to understand and map the properties and organization of the brain through the mathematics of complex networks. It applies this framework to study the properties and organization of the network of connections forming the human brain––its “connectome”––in terms of both structure and function. 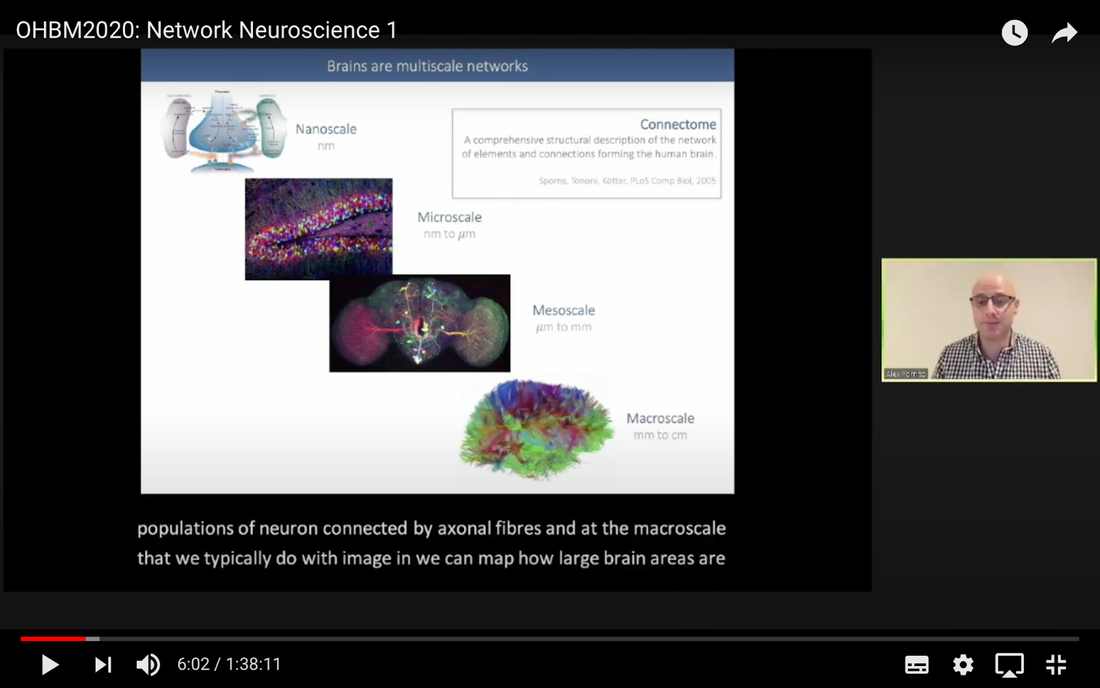 Alex Fornito describing the brain as a network at different levels of resolution Is this related to a thing called graph theory that I always get confused about? Graph theory, as Alex explains from 6:04 onwards, is a mathematical framework that can be used to study the connectivity among the core constituents of a graph, e.g., a set of “nodes” connected by “edges” that measure the association between pairs of nodes. In this sense, a graph is a structure that attempts to model the relationships between different interconnected objects (the “objects” can range from brain areas to people’s friendships) and offers a natural analysis model for any networked system. Using MRI, we can study brain networks at coarse spatial scales, in which nodes are defined as spatially focal, functionally homogeneous brain areas that are considered to be fundamental processing units of the network. In network neuroscience, nodes are also referred to as “parcels”, and a set of nodes covering the whole brain can be defined as a “brain parcellation”. Edges are defined as the connections between the nodes in the network and for MRI-based studies of the brain, these connections are representative measures of the functional and structural connectivity between brain regions. The mathematics of graph theory allows us to extract the organizational properties of the brain connectome and relate these properties to those observed in other systems found in nature. Hmm … ok that makes sense, but how are these nodes defined? Sensible node definition is perhaps the most challenging aspect of connectomics analysis as, in many instances, there are no clear boundaries visible with MRI that segregate brain areas into functionally meaningful homogeneous brain areas (Fornito and Bullmore, 2015). At 8:00 min Alex describes that the interpretation of any network analysis depends on the way in which nodes and edges are defined. Good definitions of nodes should adhere to three properties: 1. The nodes need to be spatially constrained. That is, a node should be defined as a spatially contiguous patch of the brain rather than a combination of spatially distinct regions. This is based on the assumption that neurons dedicated to any specific functionality are constrained to a specific location in the brain. 2. Each node should be intrinsically functionally homogeneous, so that the constituents of the nodes, such as voxels clustered into a single node, should share a similar function. 3. The nodes should be extrinsically distinct, so that the function of one node can be differentiated from others. 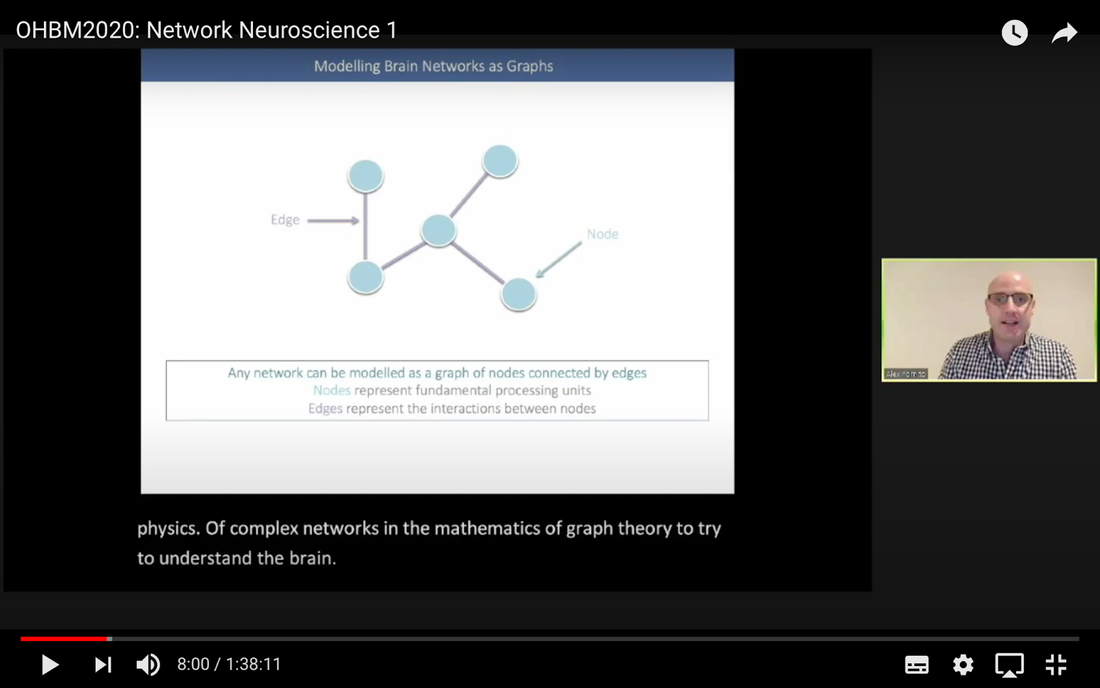 Alex Fornito explaining how we can use graphs to represent brain networks Further elaborating on the first property, at 37:54 min Janine discusses different ways to conceptualize spatially contiguous and non-contiguous nodes. Contiguous nodes are spatially interconnected voxels or vertices which form a single localized region of the brain and are consistent with the notion of functionally specialised regions. Alternatively, non-contiguous nodes are made up of various distinct areas that may be dispersed throughout the brain, for example, bilateral brain areas. This conceptualization is consistent with the hierarchical and hemispherically organised network structure of the brain. Janine goes on to explain other characteristics such as “binary” and “weighted” nodes. Nodes are considered “binary” when each voxel is a member of exactly one node only; often referred to as a “hard parcel”. Alternatively, nodes are “weighted” when a voxel can have non-zero membership to multiple nodes; often referred to as a “soft parcel”. Clustering methods such as K-means clustering and normalised cuts group voxels together based on similarity to create nodes. These nodes tend to be binary and can either be contiguous or non-contiguous. Data-driven decomposition methods, such as ICA and PCA, produce weighted parcellations that usually combine different regions in the brain (i.e. not spatially contiguous) into a single node. 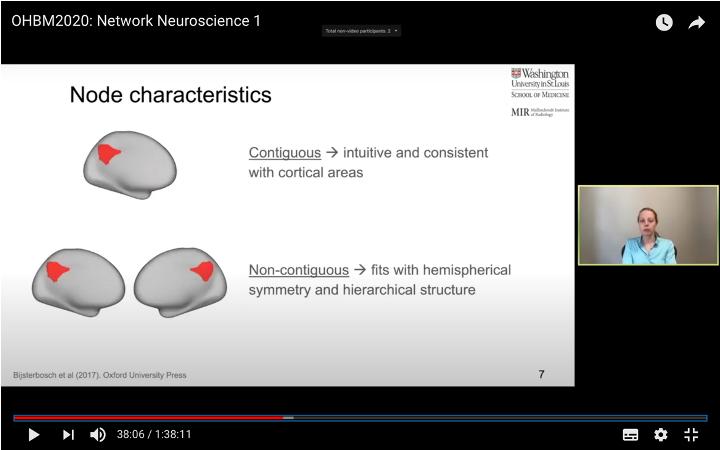 Janine Bijsterbosch discussing characteristics of nodes At 42:47 min, Janine also mentions the challenges that we have to address when defining nodes. For example, it is generally assumed that a node is a homogeneous region, the aggregate of which serves as an accurate representation of the activity that goes on throughout the different voxels in that node. However, this is questionable for different reasons: a region may be heterogeneous in both its connectivity and function. For example, if one were to average the signals across the entire primary motor cortex, a region which has homogenous cytoarchitecture, this would overlook the meaningful functional heterogeneity which encapsulates different hand and foot movements (Haak et al., 2020). For this reason, it is important to be mindful of the core assumptions that are implicit in any parcellation procedure. Right, but how can we define them in a more practical sense? Generally, nodes should be defined either using published parcellations available in literature or from your own data. At 9:26 min Alex explains different approaches by which nodes can be defined, such as cytoarchitectonic maps or sulci and gyral landmarks. There are many different published parcellation schemes and methods for parcellation of your own data that are now open access. Arslan et al. (2018) consider a variety of such anatomical, connectivity-driven, and random parcellations in their study, comparing the performance of different schemes and methods for connectomics. They conclude that there is no clear “one size fits all” winner, instead providing guidelines for the choice of the parcellation technique that may be appropriate for the problem under investigation. Similarly, at 33:34 min Janine notes that the parcellation scheme should match with the modality that you’re investigating. An advantage of using published parcellations or atlases to define nodes is that the node definitions are identical to other studies, allowing comparison with other published findings. Anatomical parcellations may also be derived from aspects of brain tissue, such as cytoarchitecture, that are not captured by functional parcellations. However, a limitation of using a structural-based atlas is that it may not represent your data as well as using your own data to produce your nodes. This is especially true for functional connectivity, as using atlas-based parcellations have been shown to have reduced performance for network analysis when compared with data-driven functional parcellations (Smith et al., 2011). Therefore, nodes should be defined in accordance with what best suits the research question and hypotheses that you want to investigate. What about the edges? At 10:43 Alex explains that when mapping brain connectivity, edges are defined by distinguishing between 3 different types of brain connectivity; structural, functional and effective connectivity. Whilst structural connectivity refers to the physical white matter tracts connecting regions, functional connectivity refers to the statistical relationship between neurophysiological signals recorded in spatially differentiated regions. Notably, the directionality of a structural connection (e.g., from one region to another) is not resolvable using MRI whereas functional connectivity can be directed or undirected. Effective connectivity describes the influence that a group of nodes can have on another group, which allows for causal interactions between different neuronal systems. Whilst functional connectivity is estimated at the level of measured physiological signals, effective connectivity is estimated at the neuronal level and requires some kind of mapping between the measured signal (e.g., BOLD fMRI) and the underlying neuronal events that generate the signals. You keep saying the word “connectivity” . Can you tell me a bit more about it? Neuroscientists use the word “connectivity” to refer to any physical connection or statistical dependency between different areas of the brain. The terms “connectivity matrix”, “similarity matrix”, “affinity matrix”, or “adjacency matrix” are used interchangeably. At 12:55 min Alex mentions some different approaches that are used to measure connectivity such as diffusion Magnetic Resonance Imaging (dMRI) and functional Magnetic Resonance Imaging (fMRI). He goes over some problems that need to be tackled in the MRI data processing pipeline, such as head motion (13:27 min) and physiological noise (17:05 min). An evaluation of different preprocessing pipelines, and their impact on results when comparing connectivity differences between patients and controls, is discussed by Parkes et al. (2018). It is important to be aware of the impact of these preprocessing steps as they will have a strong influence on analysis results. Once data are preprocessed and parcellated, you can measure functional or structural connectivity between regions and produce an adjacency matrix, in which each element of the matrix contains the measure of connectivity between each node pair, or a graph representation of this connectivity represented as node elements and lines connecting them. At 19:34 min Alex explains that these two types of representation are equivalent by giving an example of a functional connectivity matrix; the only difference between the two is the visualisation. 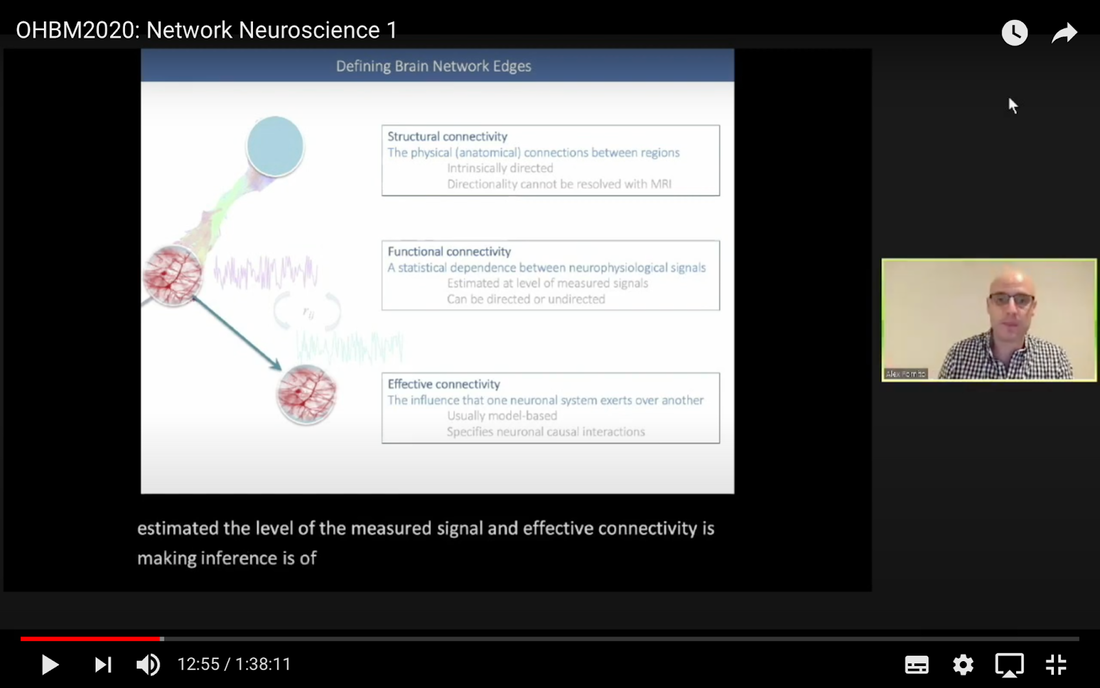 Alex Fornito explaining the different approaches used to measure connectivity But how do we measure this “connectivity”; say, for example, from functional MRI? Just as there are many ways to parcellate the brain, there are many ways to define “functional connectivity” via different statistical measures that capture the shared information (relationships) between two nodes. In addition, one can examine the average, or “static”, connectivity across the duration of the fMRI scan, which obtains a single measure of connectivity for the whole scan between each node pair, or one can examine the dynamic fluctuations in connectivity that occur on a moment-by-moment temporal scale. Seed- or parcellation-based correlation analysis and Independent Component Analysis (ICA) are two popular methods for investigating average functional connectivity based on Pearson correlations among BOLD time courses. At 1 hr 03:52 min, Shella Keiholz explains seed- and parcellation-based correlations. At its core, Pearson correlation is a simple measure which captures linear relationships between two variables; in effect one can think of it as “how well do two signals co-fluctuate”. At 1 hr 16:47 min, Shella goes on to explain ICA as a method which decomposes an fMRI dataset into the individual signal sources that give rise to the measured BOLD signals. ICA can be performed in either the spatial or the temporal domain; given the number of voxels versus the number of timepoints in a standard resting state scan, it is more common to apply spatial ICA. While spatial ICA can separate interesting signal sources (resting state networks) from artifact signals (like those from cerebrospinal fluid or subject motion), it is important to note that ICA cannot automatically determine the number of the components (or signal sources) that should be estimated by the algorithm: this “model order” or dimensionality has to be decided by the researcher doing the analysis. At 1 hr 17:57 min Shella gives an example of using ICA to show that the choice of model order affects the resulting network maps. The main advantage of ICA is that it is data-driven so can be used to investigate functional connectivity without any a priori information, such as seed selection, and it can effectively separate signal from noise. But this also means that it can be hard to interpret resulting ICA components: one must identify the components of interest versus those that represent noise from the resulting spatial maps, which may require comparing the components with published maps or drawing from other studies to interpret them. Measures of average functional connectivity, beyond Pearson correlation, that are used for seed- and parcellation-based methods are partial correlation, mutual information measures, coherence/partial coherence, and many others. Smith et al. (2011) used simulations to investigate how different network configurations, experimental protocols, confounds, and choice of connectivity measures impacts network modelling and found that partial correlations have high sensitivity to detect direct connections between nodes, directionality is difficult to estimate, and that functionally inaccurate parcellations severely degrade connectivity analyses. More information on static functional connectivity analysis can be found in the OHBM’s OnDemand How-To: Resting State fMRI Analysis blog post. In contrast to average functional connectivity, for “time-varying” or “dynamic” functional connectivity analysis, more than one measure of connectivity is obtained to capture the variations in brain connectivity over the scan duration. Dynamic connectivity can be implemented using different approaches such as window or event-based methods. There are many excellent reviews on the promises and pitfalls of dynamic connectivity methods (Hutchison et al., 2013; Preti et al., 2017; Jalilianhasanpour et al., 2021) and the utility of these methods for classification and prediction of brain disorders (Du et al., 2018). At 1 hr 23:28 min, Shella gives an example of the sliding window method, which divides time series into small time windows to calculate the correlation between BOLD signals from two areas within a small time window that slides from one time point to the next. This new time course of correlations from each window across the duration of the scan reflects the dynamic changes in connectivity that may occur between two brain areas, even in the absence of an apparent overall average connectivity between them. This approach can be extended to parcellations: in this case, an association matrix is computed for each sliding window. 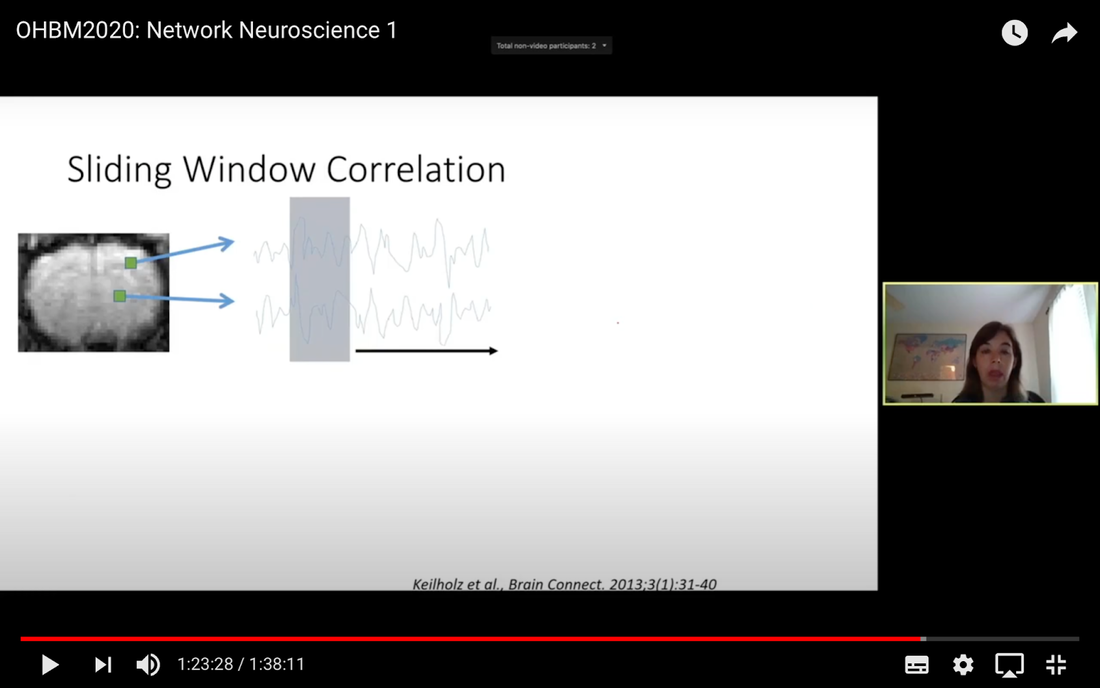 Shella Keilholz explains the sliding window correlation approach used to analyse the correlation values between two areas at different points in time Due to the number of timepoints in a typical BOLD scan, and the number of brain regions that can be considered in a parcellation scheme, data explosion is one of the main challenges of this type of analysis. Clustering can be performed as a kind of reduction step to identify a small set of brain states and their dynamic properties, either on the BOLD times series or on the association matrices. However determining the number of brain states to be estimated is subjective, similar to setting the model order for ICA. At 1 hr 36:31 min, Shella talks about these and other caveats to these functional connectivity approaches. What about structural connectivity? Structural connectivity is, conceptually, the easiest one to understand. We ask the question, is there a physical connection between one brain area and another. In more neuroscientific parlance, structural connectivity looks at the axonal tissue (white matter) that connects cortical regions to one another. While structural connectivity is what most people would intuitively think of as “connectivity”, the approaches to estimating a structural connectome can sound like a mystical art to the uninitiated. At 11:32 min Robert talks about the fundamental requirements to quantify white matter pathways. He mentions that the first requirement is to estimate the local fibre orientations in each image voxel using an appropriate diffusion model; the second is to follow the fibre orientations using a reconstruction algorithm such as streamlines tractography. This process creates trajectories through space that ideally reflect the underlying white matter connections. At 19:00 min Robert mentions that another requirement is to have a sufficiently large number of streamlines generated so that the result can be reproducible. Following reconstruction of streamlines trajectories across the entire brain white matter, structural connectome construction proceeds as follows. Firstly, each reconstructed connection must be attributed to the appropriate edge based on the nodes from the parcellation to which it is assigned. Then, one must choose the metric of connectivity to be quantified for each connectome edge; this could be the number of streamlines within that connection, samples of some quantitative metric along the corresponding streamlines trajectories, or estimates of connection density based on more advanced modelling approaches. More information on the general structural connectivity pipeline can be found in the how-to diffusion MRI blog. 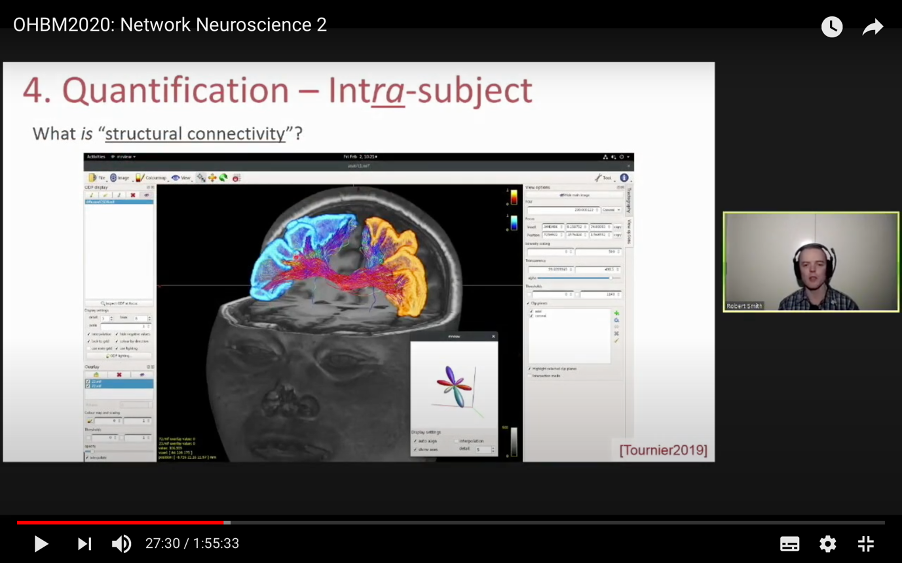 Robert Smith explaining how structural connectivity is measured So ... once a functional or structural network is obtained and the connectome is mapped, what then?! Once we have the association matrix reflecting either the functional or structural connectome, how do we characterize the properties of the network or do case-control comparisons? These questions proceed via different analyses. To characterize the properties of a network, one typically applies mathematical tools from graph theory. In many cases, the network (or association matrix) is first thresholded to remove the weakest connections from it. At 37:22 min Andrew Zalesky talks about the pros and cons of this thresholding process and at 40:56 min he gives an example of thresholding a network that has weak, moderate and strong connections. An advantage of thresholding is that the weakest connections may be false positives and so, removing them through thresholding will provide a clearer and more accurate connectome visualisation. On the other hand, one of the disadvantages of thresholding is that the choice of thresholding value is arbitrary (explained at 46:15 min) and can strongly impact the result graph theory measures. After the thresholding process, Andrew explains that the network can additionally be binarized, indicating either the presence or the absence of a connection between a pair of brain regions; alternatively, keeping the connectivity values without binarizing provides a measure of the strength of the connection between each pair of brain regions. He further explains the pros and cons of binarization. Overall there are two classes of thresholding methods: “density thresholding”, which aims to achieve a desired connection density by removing the weakest connections, and “weight thresholding”, which identifies the minimum weight a connection needs to have in order not to be removed. At 47:07 min Andrew explains other alternative approaches to connectivity strength thresholding, such as “consensus thresholding” and “local thresholding”. 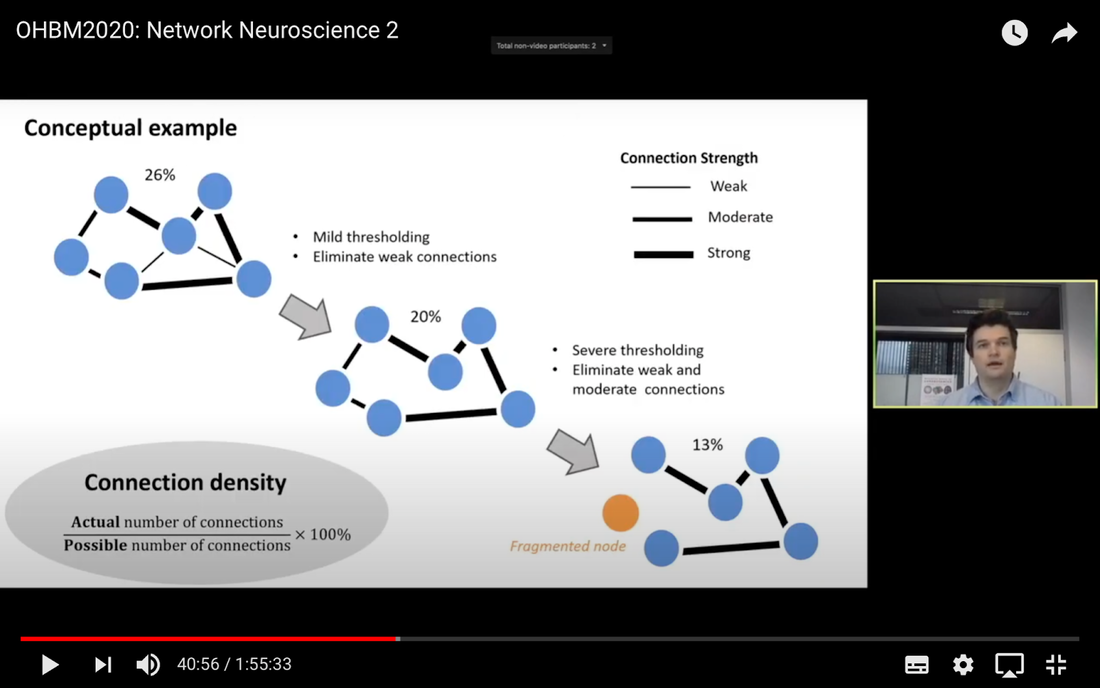 Andrew Zalesky explaining how the thresholding process eliminates weak connections Once the network is identified via thresholding (and possibly binarizing), the next step is to try to understand the organization of the network. An important concept mentioned by Andrew at 50:02 min is that null networks can be used as a benchmark of network organisation under a specific null hypothesis. For example, a random network matched for the number of nodes, edges, and possibly other network properties, can be used to understand whether a feature such as path length (the average number of nodes that must be traversed to connect any two nodes in a network) of the empirical network is unusually short, medium or long when compared with a random network. If the topology is a lattice or other kind of non-random configuration, then the path length will differ from that observed in a matched random network. The Maslov-Sneppen rewiring algorithm is further explained as a way to generate a random network matched for number of nodes, edges, and node degree (the number of edges connected to a node), which is the most common method for generating a random network as a null model. From 57:13 min onwards, Andrew explains other null models such as the geometry-preserving null model, which makes use of the impact of geometry on network topology, and generative models, which are null models that use specific wiring rules to evolve networks in silico. Inference on a specific property of the network then proceeds by sampling thousands of null networks to enable quantitative inference via Monte Carlo methods. Reconstructed connectomes can also be compared to assess group differences in connectome properties, or how connectome properties may be affected by treatment or vary with behavior. In addition, connectomes can be used to predict clinical outcomes or treatment responses. There are myriad network properties that can be assessed for differences or for prediction, ranging from connection-level to global properties of the network as Andrew describes at 1 hr 02:07 min. In contrast to connection-level analyses that examine each connection independently, network-specific attributes, such as sub-networks, may better capture differences between patients and controls, as pathology is more likely to impact sub-networks of connected nodes rather than node pairs scattered randomly around the brain. As such, network-specific attributes may also be more useful for predicting clinical outcomes or response to treatments. At 1 hr 05:26 min Andrew talks about how network-based statistics can be used to leverage network-specific attributes to enhance statistical power. So, a ‘network’ can represent the functional or structural connectivity in the brain, but it can also represent a subset of interconnected nodes referred to as “sub-networks” or “modules”. What are these modules exactly? The connectome can be conceptualized as a single large network at the macroscale or global level, or as sub-networks at the mesoscale level, or at the level of individual regions or nodes and other local-scale components. Generally speaking, at the mesoscale, ‘sub-networks’, ‘modules’, or ‘network communities’ are used interchangeably to refer to clusters of densely interconnected nodes embedded within a larger network. Though modules can be identified in social, behavioural and cellular networks, in this article the terms ‘modules’ or ‘communities’ will refer to groups of nodes reflecting organisation in the brain network. In network neuroscience, a set of strongly coupled nodes comprise structurally or functionally linked sub-networks. In most applications, nodes are strongly interconnected with each other within a sub-network, but weakly connected with nodes in the rest of the network. Understanding which nodes make up specific modules can provide significant insight into the functioning of the network. For example, changes in modular organization are related to individual differences in behaviour, development, cognitive states and disease liability. Community detection algorithms are used to discover the network’s community structure to identify subgroups of interconnected nodes. While these approaches are very flexible, detection of communities can be an ill-posed problem. At 2:07 min Richard Betzel talks about the challenges of module/community detection. One approach to detect communities in single and multi-layer networks is called “modularity maximisation”. In a single-layer network, a set of nodes is connected to each other with edges derived from a single imaging modality at one point in time. In multi-layer networks, nodes and connections can be analysed across another dimension, such as time, imaging modalities, or subjects. Ann further describes how a multilayer network works (42:54 min) and how we obtain this type of network from our data (from 50:37 min onwards). So you’re saying that the point of modularity maximisation is to get a good estimate of the communities’ network’s structure? Yes! Modularity maximisation considers communities to be groups of nodes that show stronger connections between each other within the observed network than would be expected by chance. At 4:55 min Richard explains how modularity maximisation works and further on gives examples of high-quality and low-quality partitions, in which nodes may form strong clusters or may only be weakly clustered together, respectively. For the modularity maximization approach the quality of the partition is given by the modularity quality function, Q (7:25 min). Maximizing Q corresponds to identifying a better partition into sub-networks; e.g., if the partition has a greater value of Q because of communities which are more internally dense than expected by chance, then it is considered to be of high quality. The idea is that the partition with the greatest value of Q will provide a reasonable estimate of the network’s structure. A few methodological issues, such as the choice of null model and the resolution used to detect modules, need to be considered. There are different types of null models to choose from, with the choice largely depending on the research question. In his talk (11:57 min), Richard explains how to run the Louvain algorithm with a degree-preserving null model. A challenge with modularity maximisation and other community detections algorithms is that they suffer from a resolution limit in that they are not able to detect small clusters, therefore the modules obtained by maximising Q may not reflect the networks’ actual mesoscale structure. This is explained at 15:43 min together with a solution for parameterising the modularity equation to add a resolution parameter and examine communities at different scales. Another factor to take into account for multi-layer networks (an example application to time-varying connectivity) is given at 20:37 min, which is explained by Richard from 23:57 min, is whether inter-layer coupling is defined temporally, with time-varying information within the network, or categorically, with no temporal information within the network. The weight of the temporal inter-layer coupling is under experimental control: if the multi-layer network has very weak inter-layer coupling, communities will be very versatile across layers, whilst if it’s very strong, the communities will emphasise homogeneity with little variety.  Richard Betzel explaining inter-layer coupling in multi-layer networks Martijn notes that the existence of separate modules cannot explain the complexity of neural connectivity alone (1:01:54 min). Rather, modules need to be integrated with each other through central places (or nodes) of communication. Such nodes that connect with multiple modules to facilitate integration and communication throughout the network are referred to as “hubs”.
What are “hubs”? Hubs are defined as highly connected nodes in the brain network. As Martijn describes (1:05:40 min), if we take a random network, the probability of any particular edge between two nodes being present is equivalent for all edges, and as a consequence, the number of edges present for each node (the node “degree”) is typically quite similar across all nodes; it is unlikely for there to be nodes possessing considerably more connections than others. However, in most biological networks this probability is not equal: some nodes usually have more connections than other nodes, and so these are interpreted as hubs. Martijn explains four metrics of ‘hubness’ or ‘centrality’ from 1 hr 07:36 min onwards, defining the centrality of a node via measures such as degree, closeness and betweenness. As an example, if centrality is to be identified by the degree metric, the most densely connected nodes of the networks are considered to be places of high level of centrality; there are, however, different metrics that can be used to identify centrality in both single-layer and, as explained by Ann 54:16 min, in multi-layer networks. As Bratislav points out at 1 hr 51:31 min, it is important to be aware of the assumptions being made when assigning importance to a particular network. If one assumes that communication happens when nodes communicate with their closest neighbour, then the node with the greatest degree would be chosen as an important node, or hub; conversely, if one assumes that communication happens across the shortest paths between nodes, then the node with the greatest betweenness would be chosen. The links between communication processes and measures of hubness are further explored in Bratislav’s talk. Last, once hubs are identified, they can be categorised either as “connector” or “provincial” hubs, depending on the role of the node. A connector hub refers to nodes that provide connections across modules or brain sub-networks (inter-modular connections), whilst a provincial hub refers to a node that has strong connections to the other hubs within a module (intra-modular connections). Martijn talks about this categorisation of hubs and quantitative measures reflecting node categorization from 1 hr16:19 min onwards. He further explains the two main types of interactions that may occur among the brain’s anatomical hubs, referred to as “core” and “rich club” interactions. Whilst the core refers to nodes that share the same degree (or number of connections) amongst each other, rich clubs refer to the tendency of regions with high connectivity degrees to connect densely among one another. Some limitations and caveats regarding hubs, such as the effect of community sizes on the degree of connections in modules, are also mentioned from 1 hr 32:28 min onwards. And what do all these complex topological properties mean for brain activity? In her talk, Petra Ritter provides an overview of biophysical models of large-scale brain dynamics . These models describe the activity of each brain region using biophysically-informed differential equations that describe the aggregate dynamics of populations of mutually interacting inhibitory and excitatory neurons. These populations are then ‘linked up’ according to the inter-regional connections defined by an empirical connectome dataset. The models offer a way of simulating brain activity to investigate how variations in structural connectivity affect function and to test different hypotheses about the mechanisms that drive observed activity recordings. The Virtual Brain offers a powerful and open source platform for exploring these models. So, what do I do if I’m still a bit confused but want to learn more about network science? It’s understandable that you should feel confused when trying to wrap your head around connectome construction and network analysis. As mentioned in the previous paragraphs, graph theory can be used to further our understanding of the organisation of the brain network. However, there isn’t a set roadmap for defining brain nodes and edges, or for detecting network’s modules or hubs. Though this may be a tricky process for a researcher who is trying to ensure that the right decisions are made, it allows the researcher to tailor the process to address specific research questions. For example, though there are general good practices for defining nodes (such as replicating findings using different parcellations), there isn’t an optimal approach which should always be used to define nodes because it depends on the research question being addressed. There are several online resources on network neuroscience, including two textbooks: the first by Albert-László Barabási (2016) found here, and the other by Alex Fornito, Andrew Zalesky and Ed Bullmore (2016) found here . Some papers that provide a good overview of concepts in network neuroscience are:
0 Comments
Your comment will be posted after it is approved.
Leave a Reply. |
BLOG HOME
Archives
January 2024
|
 RSS Feed
RSS Feed